Retriever vs. Reranker – was ist der Unterschied?
Wenn es darum geht, Informationen aus großen Dokumentensammlungen zu finden, hört man immer wieder die Begriffe Retriever und Reranker. Beide spielen eine entscheidende Rolle im Bereich der Retrieval-Augmented Generation (RAG), also beim Zusammenspiel von Suchtechnologie und Large Language Models (LLMs). Doch was genau unterscheidet sie voneinander?
Der Retriever – schnell und breit suchen
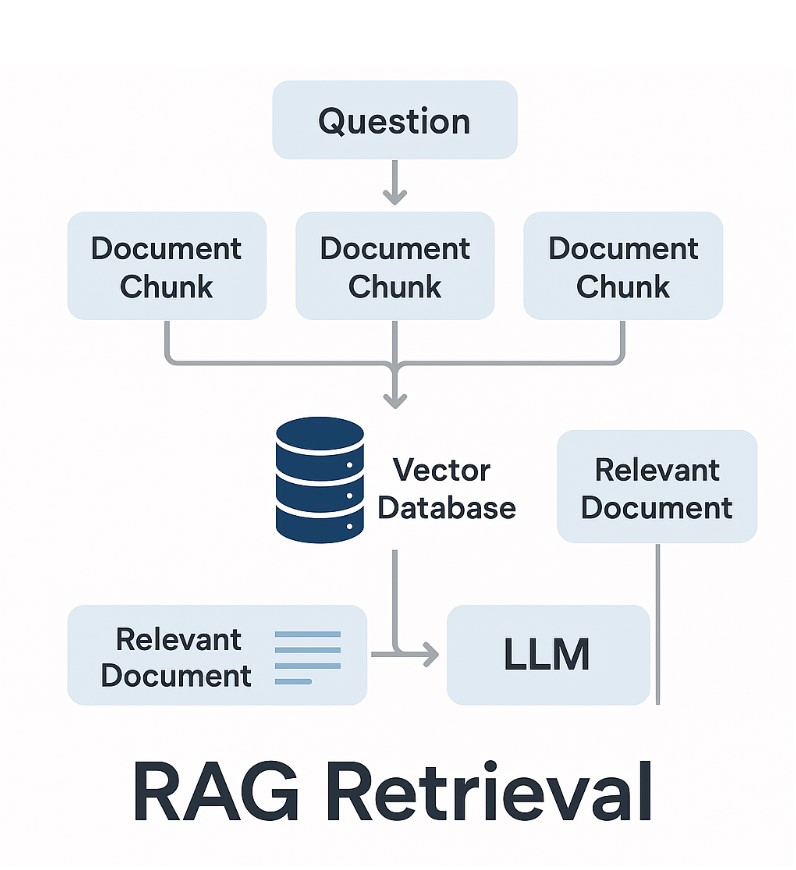
Ein Retriever ist die erste Stufe der Suche. Er hat die Aufgabe, aus einer riesigen Menge an Dokumenten oder Textpassagen die wahrscheinlich relevanten Kandidaten herauszufiltern.
Es gibt verschiedene Arten von Retrievern:
- BM25 (lexikalisch / „Sparse Retrieval“)
Arbeitet mit Schlüsselwörtern und findet Dokumente, die möglichst viele exakte Worttreffer haben. Sehr stark bei Fachtermini, Namen oder Zahlen. - Dense Retriever (semantisch / „Vektor-Suche“)
Nutzt Embeddings, um die Bedeutung von Texten zu erfassen. Dadurch findet er auch Synonyme oder inhaltlich ähnliche Formulierungen, selbst wenn die Wörter nicht exakt übereinstimmen.
Der Retriever ist also schnell und effizient, aber noch recht grob. Er bringt eine Liste von Kandidaten zurück, zum Beispiel die Top-100 Textstellen.
Der Reranker – sortieren nach echter Relevanz
Jetzt kommt die zweite Stufe ins Spiel: der Reranker.
Er nimmt die vom Retriever gefundenen Kandidaten und bewertet sie viel genauer.
Dafür verwendet er meist ein spezielles Sprachmodell (Cross-Encoder), das die Frage und den jeweiligen Text gleichzeitig betrachtet. Anschließend gibt er einen Relevanz-Score aus, also eine Zahl, die angibt, wie gut die Passage zur Frage passt.
Beispiel:
Frage: „Wie hoch ist die Kriminalität in Berlin?“
- Passage A: „Die Kriminalitätsrate in Berlin lag 2022 bei …“ → Score 0.95
- Passage B: „Berlin ist die Hauptstadt von Deutschland.“ → Score 0.05
- Passage C: „Straftaten in Hamburg sind …“ → Score 0.40
Der Reranker sortiert die Ergebnisse also so, dass das LLM am Ende nur die wirklich hilfreichen Texte lies
Zusammenspiel von Retriever und Reranker
Man kann es sich so vorstellen:
- Retriever: wie ein großes Netz, das schnell viele Fische einfängt – aber auch viel Beifang.
- Reranker: wie der Fischer, der den Fang sortiert und nur die besten Fische behält.
In modernen RAG-Pipelines werden deshalb beide kombiniert:
- Retriever holt eine breite Menge an Kandidaten.
- Reranker sortiert und filtert sie nach Relevanz.
- LLM bekommt nur die besten Passagen in den Kontext.
Das Ergebnis: präzisere Antworten, weniger Halluzinationen, zufriedene Nutzer.
Fazit
Retriever und Reranker sind keine Konkurrenten, sondern Teamplayer.
- Ohne Retriever wäre die Suche viel zu langsam.
- Ohne Reranker wären die Ergebnisse oft ungenau oder verwirrend.
Erst das Zusammenspiel beider sorgt dafür, dass LLMs in RAG-Anwendungen verlässliche Antworten geben können – auch bei großen Mengen an Dokumenten.




