-
About Me
Willkommen! Mein Name ist Michael Rifkin.Ich komme aus Wulfsen bei Hamburg und arbeite als Produktmanager und AI-Berater für große Unternehmen – derzeit mit Schwerpunkt auf Logistiklösungen. In den vergangenen Jahren lag mein Fokus auf künstlicher Intelligenz, Cloud-Technologien und Big Data – mit dem Anspruch, Innovationen nicht nur zu verstehen, sondern im Unternehmensalltag wirklich nutzbar zu machen. Schon im Alter von sieben Jahren durfte ich zum ersten Mal vor einem Computer sitzen – und war sofort von den digitalen Möglichkeiten begeistert.Damals gab es Computer eigentlich nur in großen Rechenzentren, und das Internet war für die meisten noch ein unbekannter Begriff. Die Begeisterung für IT wuchs im Laufe meiner Kindheit weiter, und…
-
Vom Prompt zum Portal – Ein ganzes Portal nur mit Vibe Coding
Vibe Coding – Spielerei oder echte Methode? Diese Frage hat mich lange gereizt. Ich wollte wissen: Kann ich mit KI nicht nur Code‑Schnipsel erzeugen, sondern ein komplettes Projekt bauen? Also habe ich es ausprobiert. Das Ergebnis ist lagepilot.de. Kurz zu mir Ich bin Informatiker. Programmieren war mal mein Alltag, aber schon lange nicht mehr mein Beruf. Python? Für mich lange ein Fremdwort. Frontend? Noch fremder. Trotzdem habe ich mir gesagt: Ich probiere es. Schritt für Schritt. In einfachen Worten. Mit KI an meiner Seite. Was ist Vibe Programming – ganz einfach erklärt Für mich bedeutet es: im Flow mit einer KI arbeiten. Keine perfekten Prompts. Stattdessen kleine, klare Schritte: So…
-
Programmieren ohne Programmieren – KI macht’s jetzt wirklich möglich!
Du willst Software bauen, ohne drei Semester Informatik und sieben YouTube-Crashkurse? Gute Nachrichten: Das geht inzwischen erstaunlich gut. KI schreibt Code, erklärt ihn, testet ihn – und ja, oft läuft das Ding sogar beim ersten Versuch. Meistens. Lass uns einmal durchgehen, warum es vor allem mit Python (Python ist eine Programmiersprache) so gut klappt, was heute schon möglich ist, wo die Grenzen liegen – und wie du ganz ohne IT-Hintergrund startest. Warum ausgerechnet Python? „Programme mit mehreren tausend Zeilen in Sekunden“ – wirklich? Kurze Antwort: Ja, KI kann sehr schnell sehr viel Code generieren.Lange Antwort: Fehlerfreiheit ist dabei kein Naturgesetz. Was heute geht: Wichtig ist die Erwartung: Vibe Coding: Von…
-
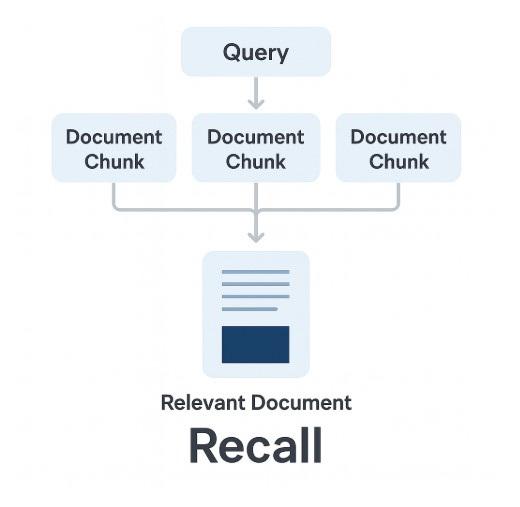
Was ist Recall in einem RAG-System?
Definition Recall ist der Anteil der tatsächlich relevanten Dokumente, die zu einer Suche gefunden wurden. Beispiel Stell dir vor, es gibt in deiner Datenbank 10 relevante Dokumente zu einer Frage: Bedeutung im RAG-Kontext Trade-off: Recall vs. Precision Beispiel aus der Medizin: Empfehlung für ein RAG-System:
-
Retriever vs. Reranker – was ist der Unterschied?
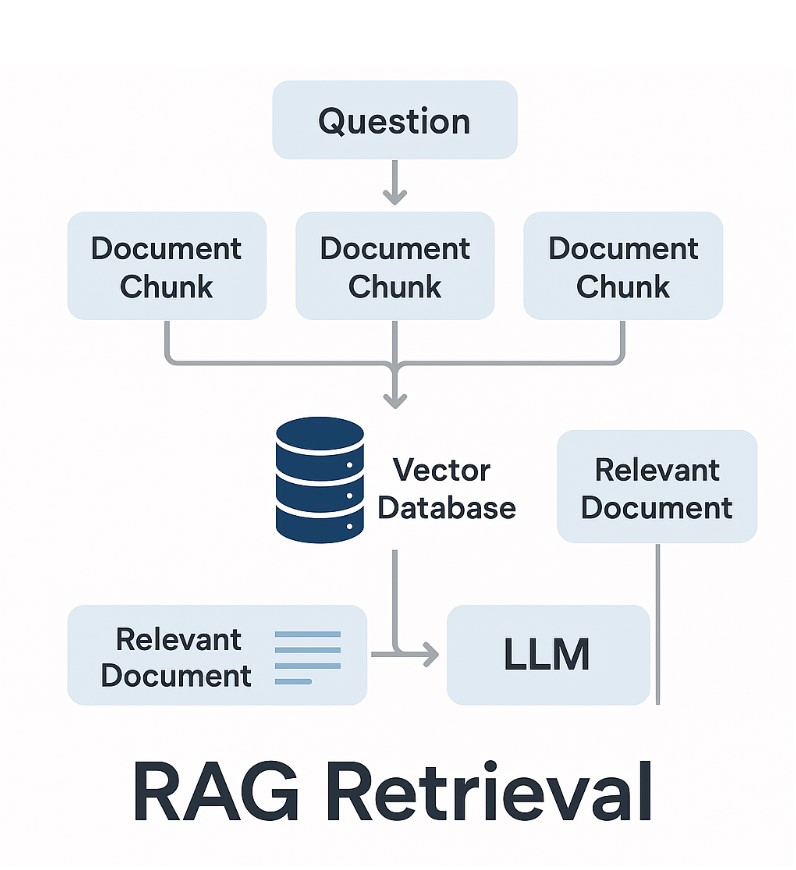
Wenn es darum geht, Informationen aus großen Dokumentensammlungen zu finden, hört man immer wieder die Begriffe Retriever und Reranker. Beide spielen eine entscheidende Rolle im Bereich der Retrieval-Augmented Generation (RAG), also beim Zusammenspiel von Suchtechnologie und Large Language Models (LLMs). Doch was genau unterscheidet sie voneinander? Der Retriever – schnell und breit suchen Ein Retriever ist die erste Stufe der Suche. Er hat die Aufgabe, aus einer riesigen Menge an Dokumenten oder Textpassagen die wahrscheinlich relevanten Kandidaten herauszufiltern. Es gibt verschiedene Arten von Retrievern: Der Retriever ist also schnell und effizient, aber noch recht grob. Er bringt eine Liste von Kandidaten zurück, zum Beispiel die Top-100 Textstellen. Der Reranker –…
-
Chunking für komplexe Berechnungen richtig einstellen
Als KI-Berater werde ich oft gefragt, wie man zum Beispiel RAGFlow optimal konfiguriert, um aus komplexen Dokumenten wie Ingenieursberechnungen das Maximum herauszuholen.Gerade bei technischen PDFs mit Formeln, Tabellen und vielen Abhängigkeiten ist die richtige Chunking-Strategie entscheidend, damit ein LLM später präzise Antworten liefern kann. Der Unterschied zwischen Aufgabenseitengröße und Chunkgröße Zunächst wird in RagFlow oft folgendes verwelchselt: Optimale Chunkgröße für Ingenieursberechnungen Bei technischen Dokumenten wollen wir ganze Rechenschritte zusammenhalten – von Annahmen über Variablendefinitionen bis zum Endergebnis. Empfehlung für diesen Use Case: RAPTOR – ja oder nein? Best Practices 💡 Fazit: Wer präzise Ergebnisse aus technischen Dokumenten will, muss die Chunkgröße in den globalen Einstellungen im Blick behalten und die…